Bartik Instrument
Shift-share IV in trade economics
August 26, 2025
Gains exist, distribution is messy
- Aggregate gains from trade are robust across HO, Ricardian, and new-trade models.
- Who gains and loses depends on factor mobility.
- HO: gains accrue to the abundant factor (Stolper-Samuelson), assuming factors move freely across industries.
- SFM (Specific Factor Model): in the short run, some factors are tied to a sector → clear winners and losers.
The textbook distinction in one line
- HO: long run, perfect mobility, factor-price equalization.
- SFM: short run, sector-specific factors, sectoral wage gaps.
- Empirical reality: the “short run” can last a decade or more, and the location of immobile factors is regional.
- This is what shift-share designs let us see in the data.
The within-country problem
- Cross-country evidence on gains from trade is settled.
- Within-country evidence is mixed and politically explosive.
- Why? Adjustment is spatial: districts, commuting zones, and provinces specialize in different sectors and absorb shocks differently.
- Reasons for imperfect mobility:
- skill mismatch (sector-specific human capital)
- geographic immobility (housing, family ties, language)
- institutional frictions (labor laws, licensing)
What we want to estimate
We want a local causal effect of a trade shock:
Yℓ=α+δXℓ+εℓ
- Yℓ — outcome in region ℓ (employment, wages, poverty)
- Xℓ — local exposure to the trade shock (e.g., change in import penetration)
- δ — the parameter we care about
Problem. Xℓ is endogenous: regions that import more are also regions where productivity, demand, or politics differ in unobserved ways.
→ We need an instrument for Xℓ.
The Bartik (shift-share) idea
Two ingredients:
- Shares sℓk — region ℓ’s pre-period exposure to sector k (employment, output, or expenditure share)
- Shifts gk — a common (national or world) shock to sector k
Combine into a single regional exposure measure:
Zℓ=∑ksℓkgk
The instrument predicts how hard region ℓ should be hit by a common shock, given its industrial structure.
Why call it “Bartik”?
- Tim Bartik (1991) used national industry growth rates interacted with local industry mix to predict local labor demand growth.
- The construct predates him (Perloff 1957, Freeman 1980) but the name stuck after Blanchard & Katz (1992) popularized it.
- In trade: replace national growth with tariff changes (Topalova) or import surges (ADH).
- Goldsmith-Pinkham, Sorkin, and Swift (2020) formalize it as a GMM problem with the shares as instruments.
A first numerical look
3 regions × 2 sectors. Tariffs fall between 1987 and 1988.
| region | LAgri | LManuf | sAgri | sManuf |
|---|---|---|---|---|
| A | 100 | 9 000 | 0.011 | 0.989 |
| B | 1 000 | 400 | 0.714 | 0.286 |
| C | 700 | 3 000 | 0.189 | 0.811 |
National tariff change 1987→1988: Agri 30 → 10, Manuf 20 → 5.
Bartik exposure Zℓ=sℓ,AgriΔlogtAgri+sℓ,ManufΔlogtManuf:
| region | Zℓ (Δlog) | Zℓ (Δlevel) |
|---|---|---|
| A | −1.38 | −15.1 |
| B | −1.18 | −18.6 |
| C | −1.33 | −15.9 |
Note the ranking flips: log change makes A most exposed; level change makes B most exposed.
What just happened?
- Manuf had the larger proportional cut: log(5/20)=−1.39 vs. log(10/30)=−1.10.
- Agri had the larger absolute cut: −20 pp vs. −15 pp.
- Which one matters? Depends on the outcome model: log-log specifications need Δlogt, level specifications need Δt.
- Lesson: the Bartik is only as well-motivated as the production-side or trade-elasticity model behind it.
First stage, reduced form, IV
The Bartik is used as an instrument:
First stage Xℓ=π0+π1Zℓ+uℓ
Reduced form Yℓ=ρ0+ρ1Zℓ+vℓ
2SLS ˆδIV=ρ1/π1
- Many papers (ADH 2013, Topalova) report the reduced-form coefficient ρ1 directly, calling Zℓ “exposure.”
- The 2SLS scaling requires π1≠0 and the exclusion restriction E[Zℓεℓ]=0.
Identification: two camps
Goldsmith-Pinkham, Sorkin, and Swift (2020) ask the central question: which assumption makes the Bartik valid?
| Camp | Source of identification | Champion paper |
|---|---|---|
| Share-based | Shares sℓk are exogenous to unobservables | Goldsmith-Pinkham, Sorkin & Swift (2020) |
| Shock-based | Shifts gk are quasi-randomly assigned | Borusyak, Hull & Jaravel (2022) |
Both deliver consistent IV under different conditions. The right diagnostic depends on which assumption you lean on.
Share exogeneity (GP framework)
Goldsmith-Pinkham, Sorkin, and Swift (2020) prove: the Bartik 2SLS estimator equals a GMM estimator where each share sℓk acts as a separate instrument, weighted by Rotemberg weights αk.
ˆδBartik=∑kαkˆδk
- ˆδk — just-identified IV using share s⋅k alone
- αk — Rotemberg weight, ∑kαk=1, can be negative
- A few industries usually carry most of the weight → the design hinges on the exogeneity of those few shares.
Rotemberg weights
For each industry k, the weight is
αk=gk⋅∑ℓsℓkXℓ∑k′gk′⋅∑ℓsℓk′Xℓ,∑kαk=1.
Two ingredients drive αk:
- size of the shift gk — industries with bigger national shocks matter more.
- first-stage covariance ∑ℓsℓkXℓ — how strongly industry k’s shares correlate with the endogenous regressor.
Weights can be negative: if gk and the first-stage covariance have opposite signs, that industry pulls the Bartik in the opposite direction. A handful of industries usually carry most of the weight.
Named for Julio Rotemberg (1983), who used the same decomposition logic in a different IV setting; Goldsmith-Pinkham, Sorkin, and Swift (2020) formalised it for the Bartik.
Rotemberg weights: 2x2
Use our toy data. Set Xℓ=Zlevℓ so the mechanics are visible: XA=−15.1,XB=−18.6,XC=−15.9, with shifts gAgri=−20,gManuf=−15.
First-stage covariances:
∑ℓsℓ,AgriXℓ=0.011(−15.1)+0.714(−18.6)+0.189(−15.9)=−16.45 ∑ℓsℓ,ManufXℓ=0.989(−15.1)+0.286(−18.6)+0.811(−15.9)=−33.15
Numerators: (−20)(−16.45)=329.0 and (−15)(−33.15)=497.2. Denominator 826.2.
αAgri=0.40,αManuf=0.60.
Manufacturing carries 60% of the Bartik. With 100+ industries in Topalova or ADH, 5–10 industries typically carry 80% of the weight — those are the shares whose exogeneity you actually need to defend.
Rotemberg weights in R
# shares: L × K matrix; g: length K; X: length L
fs_cov <- as.numeric(t(shares) %*% X) # first-stage covariances
alpha <- g * fs_cov
alpha <- alpha / sum(alpha) # Rotemberg weights
# per-industry just-identified IV
beta_k <- as.numeric(t(shares) %*% Y) / fs_cov
sum(alpha * beta_k) # = Bartik 2SLS estimateThe bartik.weight package (GitHub: paulgp/bartik-weight) does this and produces the Goldsmith-Pinkham, Sorkin, and Swift (2020) Table 5 diagnostic panel directly.
Diagnostics from Rotemberg weights
Goldsmith-Pinkham, Sorkin, and Swift (2020) recommend reporting:
- Concentration of weights — Herfindahl of |αk|. If 2–3 industries dominate, your identification is really about those industries.
- Top-5 industries — list them and ask: are their shares plausibly exogenous to local outcome trends?
- Pre-trend checks on Zℓ — does pre-shock Zℓ predict pre-shock changes in Yℓ?
- Just-identified IV by industry — if ˆδk varies wildly across top industries, the pooled estimate is fragile.
Shock exogeneity (BHJ framework)
Borusyak, Hull, and Jaravel (2022) take a different route. Treat the shifts gk as random and the shares as exposure weights.
- Identification: gk is uncorrelated with sector-average residuals.
- Works well when shifts come from outside the system you study (e.g., supply-driven Chinese import surge from China’s TFP and WTO accession).
- Diagnostic: tests for shock balance — does gk correlate with pre-shock industry characteristics?
- The ADH “instrument with other rich countries’ imports from China” exploits exactly this — it isolates the supply-driven component of the shock.
Inference: don’t use OLS standard errors
Adão, Kolesár, and Morales (2019) show that conventional cluster-robust SEs over-reject with shift-share regressors:
- Residuals are correlated across regions that share industry mix.
- Their fix: an exposure-robust SE that treats industries as the clusters of randomness.
- In R, you can implement AKM SEs via the
ShiftShareSEpackage or replicate by IV with industry-level data. - Rule of thumb for class: if you see Bartik with white SEs only, be skeptical.
Limitations to keep in mind
- Pre-period shares can be endogenous (industries locate for a reason).
- Common shocks may be heterogeneous across sub-periods → time-varying gk.
- Placebo tests on pre-period Y are essential.
- Weighting: by region size, by inverse SE, by employment — affects which observations drive the result.
- Aggregation matters: districts vs. provinces vs. commuting zones give different answers.
Topalova (2010): India 1991
- India’s 1991 liberalization cut tariffs unevenly across industries.
- Cross-district variation in pre-reform industry mix → cross-district variation in exposure.
- Difference-in-differences with Bartik exposure as the treatment.
Identification: the pace of tariff cuts was dictated by external (IMF) pressure and was negotiated industry-by-industry without regard to district outcomes → shocks plausibly exogenous to district trends.
Topalova: instrument
ZTopℓ=∑ks1987ℓkΔlog(Tariffk)
- s1987ℓk — district ℓ’s pre-reform employment share in industry k
- Δlog(Tariffk) — national log-change in industry k’s tariff between 1987 and 1997
Outcomes: district-level poverty headcount, poverty gap, consumption growth.
Topalova: specification
Topalova runs a panel across four NSS rounds (1983, 1987–88, 1993–94, 1999–2000):
Ydt=αd+γst+δTariffdt+W′dtλ+εdt
with district tariff constructed Bartik-style,
Tariffdt=∑ksdk,1987⋅Tariffkt
- αd — district FE (kill all time-invariant district traits)
- γst — state × year FE (absorb state-wide trends)
- shares frozen at 1987; national tariffs Tariffkt vary year-by-year
- IV: instrument realised tariffs with the scheduled tariff reduction path
Under two-way FE this is numerically equivalent to a long-difference regression on ΔYd vs. ΔTariffd — which is why ADH-style papers (and teaching slides) often present Bartik in differences.
Topalova: findings
- Rural districts more exposed to tariff cuts → slower decline in poverty, lower consumption growth.
- Effect concentrated among the geographically immobile and least skilled.
- Mechanism: rigid labor laws → costly to fire and to expand → factor reallocation stalls.
- In states with flexible labor regulation, the poverty effect of exposure is statistically zero.
Takeaway: Bartik captures exposure; institutions decide adjustment.
Autor, Dorn & Hanson (2013): the China shock
- Autor, Dorn, and Hanson (2013) examine US commuting zones (CZs) 1990–2007.
- China’s WTO accession (2001) and supply-side reforms drove a sustained import surge.
- Variation across CZs comes from pre-shock industry mix.
ADH: the instrument
ΔIPWcτ=∑kLck,t0Lk,t0⋅ΔMUSkτLc,t0
- Lck,t0 — start-of-period employment in CZ c, industry k
- ΔMUSkτ — change in US imports from China in industry k
To address shock endogeneity (US demand could pull in imports too), ADH instrument ΔMUS with ΔMOTH — imports from China to eight other rich countries. This isolates the China-side supply shock.
ADH: main results
- High-exposure CZs lose more manufacturing jobs.
- Wages fall, esp. among non-college workers.
- No offsetting employment gains in other sectors at the local level.
- Effects persist for at least a decade.
- Autor, Dorn, and Hanson (2016) (2016 review) extends to job churning, lifetime earnings, social spending, marriage rates, mortality.
Why ADH matters methodologically
- Cleanest example of the shock-based identification logic in BHJ.
- The “other rich countries” instrument is the canonical move for purging demand-side endogeneity from a Bartik.
- Sparked the AKM (2019) literature on inference because their headline SEs were too tight.
- Their data and Stata replication files are widely used in teaching.
Kis-Katos & Sparrow (2015): Indonesia 1993–2002
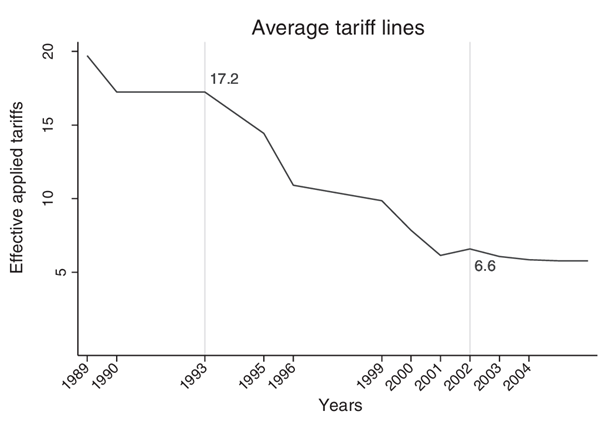
- 259 districts; outcome is district-level poverty.
- Two waves of tariff cuts: WTO 1995 + IMF program 1999.
- Innovation: separate output and input tariff exposure using a 1990 input-output table.
Output vs. input tariffs
Otkt=S∑s=1(Qsk,t=0Qk,t=0×tst)
Itkt=S∑s=1(Qsk,t=0Qk,t=0×J∑j=1Mjs,1990Ms,1990tjt)
sector s, district k, time t, input sector j, labor Q, tariff t
The first share weights output tariffs by district industry mix; the second additionally weights through the I-O matrix to capture imported intermediate inputs embodied in each sector.
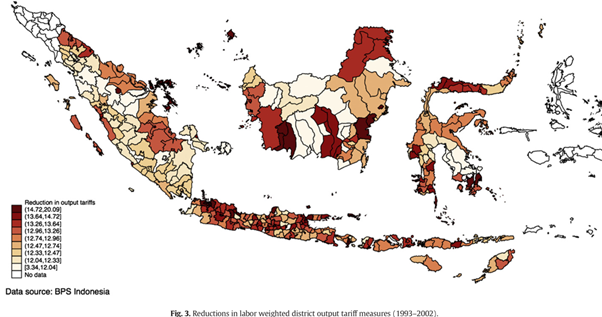
Output tariff exposure
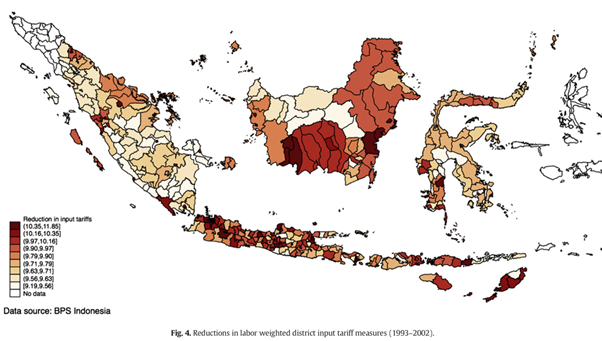
Input tariff exposure
Kis-Katos & Sparrow: findings
Δykt=α+β1Otkt+β2Itkt+γΔX′kt+I′kθ+λrt+Δϵkt
- β1>0 — output tariff cuts raise poverty (import competition story).
- β2<0 and larger in magnitude — input tariff cuts reduce poverty (cheaper intermediates → firm competitiveness → low-skill work participation and middle-skill wages rise).
Net effect on Indonesian poverty is negative — but only because input tariff liberalization dominates. The distributional story matters.
Three applications side by side
| Topalova (2010) | ADH (2013) | KK & Sparrow (2015) | |
|---|---|---|---|
| Country | India | US | Indonesia |
| Episode | 1991 reform | 1990–2007 | 1993–2002 |
| Unit | districts | commuting zones | districts (259) |
| Shock | tariff cuts | China imports | tariff cuts (2 waves) |
| Share | 1987 employment | start-period emp. | I-O × employment |
| Outcome | poverty, consumption | jobs, wages | poverty |
| Direction | exposure ↑ → poverty ↑ | exposure ↑ → jobs ↓ | output↑ poverty↑, input↓ poverty↓ |
Hands-on with R
The dataset
dat.xlsx — 3 regions, 2 sectors, 2 years. Toy data so you can verify by hand.
# A tibble: 12 × 5
year region sector tariff labor
<dbl> <chr> <chr> <dbl> <dbl>
1 1987 A Agri 30 100
2 1987 B Agri 30 1000
3 1987 C Agri 30 700
4 1987 A Manuf 20 9000
5 1987 B Manuf 20 400
6 1987 C Manuf 20 3000
7 1988 A Agri 10 110
8 1988 B Agri 10 1100
...Step 1 — compute 1987 employment shares
Step 2 — compute national tariff shocks
Step 3 — assemble the Bartik
# A tibble: 3 × 3
region Z_log Z_lev
<chr> <dbl> <dbl>
1 A -1.38 -15.1
2 B -1.18 -18.6
3 C -1.33 -15.9Region A is most exposed in log, region B most exposed in levels — same point we made earlier, now in code.
Step 4 — the (would-be) 2SLS
With only 3 districts there’s nothing to estimate. In a real Topalova-style exercise:
For AKM-corrected SEs, use the ShiftShareSE package and pass the share matrix.
Exercise (10 min, in pairs)
Using only dat.xlsx:
- Recompute Zℓ assuming the 1988 shares (not 1987). What’s different and why?
- Now compute it using employment growth as the shift instead of tariffs. Does the ranking of regions change?
- Region A is essentially a “manufacturing town.” If we drop A, what happens to the cross-sectional variation in Z? What does that tell you about the Rotemberg-weight diagnostic in GP?
- Suppose we observed poverty rates falling by 5pp in A, 2pp in B, 4pp in C. Compute the reduced-form slope of Δpoverty on Zℓ. Interpret with care — what assumption are you making?
What to read next
- Goldsmith-Pinkham, Sorkin, and Swift (2020) — the canonical methods paper. Tables 5–6 are the diagnostic template you should copy in your own work.
- Borusyak, Hull, and Jaravel (2022) — when shocks (not shares) carry identification.
- Adão, Kolesár, and Morales (2019) — the inference paper. The R package
ShiftShareSEimplements it. - Autor, Dorn, and Hanson (2013) + Autor, Dorn, and Hanson (2016) (review) — the China shock canon.
- Topalova (2010) — the trade-and-poverty workhorse for developing countries.
- Kis-Katos and Sparrow (2015) — the closest Indonesian benchmark for your own work.
Frontier and Indonesian context
- I-O Bartik: extend KK & Sparrow’s input/output split to services value-added (GVC trade).
- Granular instruments: large firms as shock units instead of sectors (Gabaix-Koijen 2024).
- Uncertainty as a shift: ongoing work by Pane, Massie & Gupta (2025) uses a geopolitical uncertainty index in place of tariff changes — the share captures exposure to uncertain trading partners rather than to specific industries (Pane, Massie, and Gupta 2025).
- Whatever the shift, the identification logic is the same: argue for either share exogeneity or shock exogeneity, then show diagnostics consistent with that argument.
Wrap-up
- Bartik = shares × shifts → predicted regional exposure.
- Two identification stories; pick one and live by it.
- Always report Rotemberg weights or shock-balance tests.
- Use AKM SEs, not white SEs.
- The trade-policy applications (Topalova, ADH, KK & Sparrow) give you a recipe you can transplant onto any Indonesian liberalization episode.