Dataviz (kependekan dari data visualization) merupakan teknik yang digunakan untuk mempresentasikan data dalam bentuk yang lebih user friendly atau lebih enak dilihat oleh manusia.
Dataviz ga ada gunanya untuk regresi di R. Fungsinya simply untuk komunikasi dengan manusia.
Seringkali, dataviz bahkan lebih penting dari analisis regresi!
Step dataviz
Cari datanya dulu! Apa yang mau di-viz-in kalo datanya gak ada?
Tentukan viz yang paling cocok.
Koneksikan viz dengan cerita/narasi tulisan anda!
A picture worth a thousand words!
Fungsi umum dataviz
menunjukkan hubungan dua atau lebih data untuk analisis awal
hubungan seperti ini ujung-ujungnya harus menggunakan regresi.
Menunjukkan tren / growth / perubahan data poin sepanjang waktu.
misalnya nilai tukar dari bulan ke bulan apakah stabil, naik, atau turun.
perubahan harga, perubahan PDB, dan lain-lain
Menunjukkan fraction/berapa besar data 1 observasi dibandingkan total.
seberapa besar ekspor batubara dibanding keseluruhan ekspor Indonesia?
Tools
Tools paling standard adalah microsoft excel!
R punya native command plot tapi fungsinya agak terbatas, terutama untuk time series.
Di R, penggunaan ggplot sangat disarankan.
ggplot merupakan bagian dari package tidyverse
install dan liberary tidyverse sudah cukup untuk memakai ggplot
Excel
explore di tab “insert”
ggplot
Untuk pengguna R, ggplot merupakan pilihan favorit, terutama jika anda menggunakan api call via R seperti WDI
ggplot jauh lebih versatile daripada plot, dapat langsung diinput di .qmd, tapi juga bisa disave ke .png untuk digunakan di word.
Namun sedikit problemnya adalah syntax-nya ggplot agak ribet.
Syntax ggplot
Di kuliah ini, anda akan diberikan kode yang bisa tinggal copy-paste.
Namun untuk bisa menguasai ggplot dengan penuh, anda perlu kuliah sendiri tentang dataviz, atau bisa juga otodidak (seperti saya)
Ada banyak buku untuk belajar ggplot yang gratis, juga course online.
Jika anda sudah paham syntaxnya, maka mengandalkan google saja cukup (seperti saya)
Syntax dasar
syntax dasar ggplot dibuka denga command ggplot(data,aes()) dan diikuti tanda tambah.
command ggplot() berfungsi untuk menginformasikan ke R bahwa anda ingin memulai gambar dengan data ini.
kita akan coba contoh yang cocok dengan cross section
Data
Data ini sama dengan di pertemuan 1, yaitu data cross-section.
library(WDI)library(tidyverse)indi<-c( # membuat dictionary"PDB"="NY.GDP.MKTP.CD","import"="NE.IMP.GNFS.CD")dat<-WDI( # Menarik data World Bankcountry="all",indicator=indi,start=2019,end=2019,)dat
country iso2c iso3c year
1 Afghanistan AF AFG 2019
2 Africa Eastern and Southern ZH AFE 2019
3 Africa Western and Central ZI AFW 2019
4 Albania AL ALB 2019
5 Algeria DZ DZA 2019
6 American Samoa AS ASM 2019
7 Andorra AD AND 2019
8 Angola AO AGO 2019
9 Antigua and Barbuda AG ATG 2019
10 Arab World 1A ARB 2019
11 Argentina AR ARG 2019
12 Armenia AM ARM 2019
13 Aruba AW ABW 2019
14 Australia AU AUS 2019
15 Austria AT AUT 2019
16 Azerbaijan AZ AZE 2019
17 Bahamas, The BS BHS 2019
18 Bahrain BH BHR 2019
19 Bangladesh BD BGD 2019
20 Barbados BB BRB 2019
21 Belarus BY BLR 2019
22 Belgium BE BEL 2019
23 Belize BZ BLZ 2019
24 Benin BJ BEN 2019
25 Bermuda BM BMU 2019
26 Bhutan BT BTN 2019
27 Bolivia BO BOL 2019
28 Bosnia and Herzegovina BA BIH 2019
29 Botswana BW BWA 2019
30 Brazil BR BRA 2019
31 British Virgin Islands VG VGB 2019
32 Brunei Darussalam BN BRN 2019
33 Bulgaria BG BGR 2019
34 Burkina Faso BF BFA 2019
35 Burundi BI BDI 2019
36 Cabo Verde CV CPV 2019
37 Cambodia KH KHM 2019
38 Cameroon CM CMR 2019
39 Canada CA CAN 2019
40 Caribbean small states S3 CSS 2019
41 Cayman Islands KY CYM 2019
42 Central African Republic CF CAF 2019
43 Central Europe and the Baltics B8 CEB 2019
44 Chad TD TCD 2019
45 Channel Islands JG CHI 2019
46 Chile CL CHL 2019
47 China CN CHN 2019
48 Colombia CO COL 2019
49 Comoros KM COM 2019
50 Congo, Dem. Rep. CD COD 2019
51 Congo, Rep. CG COG 2019
52 Costa Rica CR CRI 2019
53 Cote d'Ivoire CI CIV 2019
54 Croatia HR HRV 2019
55 Cuba CU CUB 2019
56 Curacao CW CUW 2019
57 Cyprus CY CYP 2019
58 Czechia CZ CZE 2019
59 Denmark DK DNK 2019
60 Djibouti DJ DJI 2019
61 Dominica DM DMA 2019
62 Dominican Republic DO DOM 2019
63 Early-demographic dividend V2 EAR 2019
64 East Asia & Pacific (excluding high income) 4E EAP 2019
65 East Asia & Pacific (IDA & IBRD countries) T4 TEA 2019
66 East Asia & Pacific Z4 EAS 2019
67 Ecuador EC ECU 2019
68 Egypt, Arab Rep. EG EGY 2019
69 El Salvador SV SLV 2019
70 Equatorial Guinea GQ GNQ 2019
71 Eritrea ER ERI 2019
72 Estonia EE EST 2019
73 Eswatini SZ SWZ 2019
74 Ethiopia ET ETH 2019
75 Euro area XC EMU 2019
76 Europe & Central Asia (excluding high income) 7E ECA 2019
77 Europe & Central Asia (IDA & IBRD countries) T7 TEC 2019
78 Europe & Central Asia Z7 ECS 2019
79 European Union EU EUU 2019
80 Faroe Islands FO FRO 2019
81 Fiji FJ FJI 2019
82 Finland FI FIN 2019
83 Fragile and conflict affected situations F1 FCS 2019
84 France FR FRA 2019
85 French Polynesia PF PYF 2019
86 Gabon GA GAB 2019
87 Gambia, The GM GMB 2019
88 Georgia GE GEO 2019
89 Germany DE DEU 2019
90 Ghana GH GHA 2019
91 Gibraltar GI GIB 2019
92 Greece GR GRC 2019
93 Greenland GL GRL 2019
94 Grenada GD GRD 2019
95 Guam GU GUM 2019
96 Guatemala GT GTM 2019
97 Guinea-Bissau GW GNB 2019
98 Guinea GN GIN 2019
99 Guyana GY GUY 2019
100 Haiti HT HTI 2019
101 Heavily indebted poor countries (HIPC) XE HPC 2019
102 High income XD 2019
103 Honduras HN HND 2019
104 Hong Kong SAR, China HK HKG 2019
105 Hungary HU HUN 2019
106 IBRD only XF IBD 2019
107 Iceland IS ISL 2019
108 IDA & IBRD total ZT IBT 2019
109 IDA blend XH IDB 2019
110 IDA only XI IDX 2019
111 IDA total XG IDA 2019
112 India IN IND 2019
113 Indonesia ID IDN 2019
114 Iran, Islamic Rep. IR IRN 2019
115 Iraq IQ IRQ 2019
116 Ireland IE IRL 2019
117 Isle of Man IM IMN 2019
118 Israel IL ISR 2019
119 Italy IT ITA 2019
120 Jamaica JM JAM 2019
121 Japan JP JPN 2019
122 Jordan JO JOR 2019
123 Kazakhstan KZ KAZ 2019
124 Kenya KE KEN 2019
125 Kiribati KI KIR 2019
126 Korea, Dem. People's Rep. KP PRK 2019
127 Korea, Rep. KR KOR 2019
128 Kosovo XK XKX 2019
129 Kuwait KW KWT 2019
130 Kyrgyz Republic KG KGZ 2019
131 Lao PDR LA LAO 2019
132 Late-demographic dividend V3 LTE 2019
133 Latin America & Caribbean (excluding high income) XJ LAC 2019
134 Latin America & Caribbean ZJ LCN 2019
135 Latin America & the Caribbean (IDA & IBRD countries) T2 TLA 2019
136 Latvia LV LVA 2019
137 Least developed countries: UN classification XL LDC 2019
138 Lebanon LB LBN 2019
139 Lesotho LS LSO 2019
140 Liberia LR LBR 2019
141 Libya LY LBY 2019
142 Liechtenstein LI LIE 2019
143 Lithuania LT LTU 2019
144 Low & middle income XO LMY 2019
145 Low income XM 2019
146 Lower middle income XN 2019
147 Luxembourg LU LUX 2019
148 Macao SAR, China MO MAC 2019
149 Madagascar MG MDG 2019
150 Malawi MW MWI 2019
151 Malaysia MY MYS 2019
152 Maldives MV MDV 2019
153 Mali ML MLI 2019
154 Malta MT MLT 2019
155 Marshall Islands MH MHL 2019
156 Mauritania MR MRT 2019
157 Mauritius MU MUS 2019
158 Mexico MX MEX 2019
159 Micronesia, Fed. Sts. FM FSM 2019
160 Middle East & North Africa (excluding high income) XQ MNA 2019
161 Middle East & North Africa (IDA & IBRD countries) T3 TMN 2019
162 Middle East & North Africa ZQ MEA 2019
163 Middle income XP MIC 2019
164 Moldova MD MDA 2019
165 Monaco MC MCO 2019
166 Mongolia MN MNG 2019
167 Montenegro ME MNE 2019
168 Morocco MA MAR 2019
169 Mozambique MZ MOZ 2019
170 Myanmar MM MMR 2019
171 Namibia NA NAM 2019
172 Nauru NR NRU 2019
173 Nepal NP NPL 2019
174 Netherlands NL NLD 2019
175 New Caledonia NC NCL 2019
176 New Zealand NZ NZL 2019
177 Nicaragua NI NIC 2019
178 Niger NE NER 2019
179 Nigeria NG NGA 2019
180 North America XU NAC 2019
181 North Macedonia MK MKD 2019
182 Northern Mariana Islands MP MNP 2019
183 Norway NO NOR 2019
184 Not classified XY 2019
185 OECD members OE OED 2019
186 Oman OM OMN 2019
187 Other small states S4 OSS 2019
188 Pacific island small states S2 PSS 2019
189 Pakistan PK PAK 2019
190 Palau PW PLW 2019
191 Panama PA PAN 2019
192 Papua New Guinea PG PNG 2019
193 Paraguay PY PRY 2019
194 Peru PE PER 2019
195 Philippines PH PHL 2019
196 Poland PL POL 2019
197 Portugal PT PRT 2019
198 Post-demographic dividend V4 PST 2019
199 Pre-demographic dividend V1 PRE 2019
200 Puerto Rico PR PRI 2019
201 Qatar QA QAT 2019
202 Romania RO ROU 2019
203 Russian Federation RU RUS 2019
204 Rwanda RW RWA 2019
205 Samoa WS WSM 2019
206 San Marino SM SMR 2019
207 Sao Tome and Principe ST STP 2019
208 Saudi Arabia SA SAU 2019
209 Senegal SN SEN 2019
210 Serbia RS SRB 2019
211 Seychelles SC SYC 2019
212 Sierra Leone SL SLE 2019
213 Singapore SG SGP 2019
214 Sint Maarten (Dutch part) SX SXM 2019
215 Slovak Republic SK SVK 2019
216 Slovenia SI SVN 2019
217 Small states S1 SST 2019
218 Solomon Islands SB SLB 2019
219 Somalia SO SOM 2019
220 South Africa ZA ZAF 2019
221 South Asia (IDA & IBRD) T5 TSA 2019
222 South Asia 8S SAS 2019
223 South Sudan SS SSD 2019
224 Spain ES ESP 2019
225 Sri Lanka LK LKA 2019
226 St. Kitts and Nevis KN KNA 2019
227 St. Lucia LC LCA 2019
228 St. Martin (French part) MF MAF 2019
229 St. Vincent and the Grenadines VC VCT 2019
230 Sub-Saharan Africa (excluding high income) ZF SSA 2019
231 Sub-Saharan Africa (IDA & IBRD countries) T6 TSS 2019
232 Sub-Saharan Africa ZG SSF 2019
233 Sudan SD SDN 2019
234 Suriname SR SUR 2019
235 Sweden SE SWE 2019
236 Switzerland CH CHE 2019
237 Syrian Arab Republic SY SYR 2019
238 Tajikistan TJ TJK 2019
239 Tanzania TZ TZA 2019
240 Thailand TH THA 2019
241 Timor-Leste TL TLS 2019
242 Togo TG TGO 2019
243 Tonga TO TON 2019
244 Trinidad and Tobago TT TTO 2019
245 Tunisia TN TUN 2019
246 Turkiye TR TUR 2019
247 Turkmenistan TM TKM 2019
248 Turks and Caicos Islands TC TCA 2019
249 Tuvalu TV TUV 2019
250 Uganda UG UGA 2019
251 Ukraine UA UKR 2019
252 United Arab Emirates AE ARE 2019
253 United Kingdom GB GBR 2019
254 United States US USA 2019
255 Upper middle income XT 2019
256 Uruguay UY URY 2019
257 Uzbekistan UZ UZB 2019
258 Vanuatu VU VUT 2019
259 Venezuela, RB VE VEN 2019
260 Vietnam VN VNM 2019
261 Virgin Islands (U.S.) VI VIR 2019
262 West Bank and Gaza PS PSE 2019
263 World 1W WLD 2019
264 Yemen, Rep. YE YEM 2019
265 Zambia ZM ZMB 2019
266 Zimbabwe ZW ZWE 2019
PDB import
1 1.890449e+10 NA
2 1.001017e+12 2.648635e+11
3 7.947191e+11 2.070626e+11
4 1.540183e+10 6.926962e+09
5 1.717674e+11 4.997419e+10
6 6.470000e+08 6.140000e+08
7 3.155065e+09 NA
8 6.930911e+10 1.180943e+10
9 1.687533e+09 1.156390e+09
10 2.818502e+12 1.087714e+12
11 4.477546e+11 6.584561e+10
12 1.361929e+10 7.458381e+09
13 3.368970e+09 2.425195e+09
14 1.392228e+12 3.017680e+11
15 4.446212e+11 2.317756e+11
16 4.817424e+10 1.771247e+10
17 1.319280e+10 4.780000e+09
18 3.865332e+10 2.520771e+10
19 3.512385e+11 6.492044e+10
20 5.324250e+09 2.021650e+09
21 6.440965e+10 4.235309e+10
22 5.358309e+11 4.381723e+11
23 2.416500e+09 1.200500e+09
24 1.439169e+10 4.900485e+09
25 7.423465e+09 1.916492e+09
26 2.535657e+09 1.221922e+09
27 4.089532e+10 1.285342e+10
28 2.020248e+10 1.115803e+10
29 1.669593e+10 7.694758e+09
30 1.873274e+12 2.766328e+11
31 NA NA
32 1.346942e+10 6.810628e+09
33 6.891588e+10 4.183585e+10
34 1.617816e+10 5.023005e+09
35 2.576519e+09 6.146072e+08
36 1.981846e+09 1.293310e+09
37 2.708939e+10 1.692145e+10
38 3.967098e+10 9.333955e+09
39 1.742015e+12 5.836417e+11
40 7.742842e+10 NA
41 5.943589e+09 2.695788e+09
42 2.221301e+09 7.621378e+08
43 1.675084e+12 1.000771e+12
44 1.131495e+10 4.280251e+09
45 NA NA
46 2.785847e+11 8.272251e+10
47 1.427994e+13 2.496148e+12
48 3.231095e+11 7.008406e+10
49 1.195020e+09 3.524665e+08
50 5.177583e+10 1.520526e+10
51 1.275034e+10 6.778504e+09
52 6.441767e+10 2.024983e+10
53 5.853942e+10 1.324433e+10
54 6.232798e+10 3.179099e+10
55 1.034280e+11 1.097100e+10
56 2.995185e+09 NA
57 2.594450e+10 1.957826e+10
58 2.525482e+11 1.714581e+11
59 3.464987e+11 1.787159e+11
60 3.088854e+09 4.763669e+09
61 6.115370e+08 NA
62 8.894130e+10 2.485186e+10
63 1.163787e+13 3.079889e+12
64 1.720786e+13 3.685714e+12
65 1.718573e+13 3.678093e+12
66 2.702830e+13 7.104825e+12
67 1.081080e+11 2.489560e+10
68 3.030809e+11 7.801253e+10
69 2.688114e+10 1.238847e+10
70 1.136413e+10 4.971586e+09
71 NA NA
72 3.108190e+10 2.171688e+10
73 4.495264e+09 1.931359e+09
74 9.591259e+10 2.002206e+10
75 1.341817e+13 6.002431e+12
76 3.248640e+12 9.459736e+11
77 4.158042e+12 1.383897e+12
78 2.290998e+13 9.595047e+12
79 1.569340e+13 7.195291e+12
80 3.275707e+09 1.726437e+09
81 5.481675e+09 3.209498e+09
82 2.685149e+11 1.066669e+11
83 1.794324e+12 5.077103e+11
84 2.728870e+12 8.882314e+11
85 6.001385e+09 2.116543e+09
86 1.687441e+10 3.711866e+09
87 1.813608e+09 6.243937e+08
88 1.747044e+10 1.114280e+10
89 3.888226e+12 1.594826e+12
90 6.833754e+10 2.690804e+10
91 NA NA
92 2.052570e+11 8.574467e+10
93 2.994332e+09 1.533061e+09
94 1.213485e+09 NA
95 6.366000e+09 3.552000e+09
96 7.717042e+10 2.153475e+10
97 1.439638e+09 5.050919e+08
98 1.344286e+10 5.830608e+09
99 5.173760e+09 NA
100 1.478584e+10 5.536983e+09
101 7.978158e+11 2.527622e+11
102 5.527293e+13 1.681355e+13
103 2.508998e+10 1.457955e+10
104 3.630525e+11 6.393474e+11
105 1.639886e+11 1.299396e+11
106 3.125063e+13 7.453361e+12
107 2.482610e+10 9.892297e+09
108 3.359040e+13 8.086517e+12
109 1.042643e+12 2.321061e+11
110 1.297064e+12 4.012683e+11
111 2.339707e+12 6.342650e+11
112 2.831552e+12 6.023149e+11
113 1.119100e+12 2.130346e+11
114 2.837467e+11 7.737905e+10
115 2.336361e+11 7.228250e+10
116 3.993217e+11 4.966358e+11
117 7.315388e+09 NA
118 4.024705e+11 1.088600e+11
119 2.011302e+12 5.687271e+11
120 1.583077e+10 8.243798e+09
121 5.123318e+12 9.085919e+11
122 4.499399e+10 2.196352e+10
123 1.816672e+11 5.162914e+10
124 1.003797e+11 2.040867e+10
125 1.779353e+08 1.808184e+08
126 NA NA
127 1.651423e+12 6.024602e+11
128 7.899879e+09 4.458755e+09
129 1.361968e+11 6.113806e+10
130 8.871026e+09 5.689781e+09
131 1.874056e+10 NA
132 2.304700e+13 5.998089e+12
133 4.773980e+12 1.144249e+12
134 5.618711e+12 1.396666e+12
135 5.367417e+12 1.315744e+12
136 3.434396e+10 2.076912e+10
137 1.142534e+12 3.218793e+11
138 5.195374e+10 2.182063e+10
139 2.453981e+09 2.230203e+09
140 3.319597e+09 NA
141 6.925231e+10 2.449732e+10
142 6.427249e+09 NA
143 5.475151e+10 3.942493e+10
144 3.207007e+13 7.486012e+12
145 4.790636e+11 1.531637e+11
146 7.908593e+12 2.165288e+12
147 6.982564e+10 1.211630e+11
148 5.520476e+10 1.759358e+10
149 1.410466e+10 4.820540e+09
150 1.102537e+10 NA
151 3.651751e+11 2.108915e+11
152 5.609401e+09 4.399141e+09
153 1.728025e+10 6.558445e+09
154 1.572585e+10 2.031792e+10
155 2.320923e+08 2.670904e+08
156 8.066126e+09 4.404481e+09
157 1.443635e+10 7.538247e+09
158 1.269012e+12 4.958798e+11
159 4.120000e+08 3.027000e+08
160 1.393810e+12 4.544985e+11
161 1.376677e+12 4.453368e+11
162 3.472361e+12 1.283901e+12
163 3.159034e+13 7.331642e+12
164 1.197135e+10 6.624661e+09
165 7.383746e+09 NA
166 1.420636e+10 9.259603e+09
167 5.542054e+09 3.602221e+09
168 1.289199e+11 5.402398e+10
169 1.539004e+10 1.227056e+10
170 6.869776e+10 2.081490e+10
171 1.254193e+10 5.832030e+09
172 1.187241e+08 1.194393e+08
173 3.418619e+10 1.417687e+10
174 9.101943e+11 6.620113e+11
175 9.438131e+09 NA
176 2.134346e+11 5.767010e+10
177 1.259664e+10 6.245815e+09
178 1.291646e+10 3.396076e+09
179 4.481200e+11 8.874099e+10
180 2.313041e+13 3.702793e+12
181 1.260634e+10 9.602018e+09
182 1.182000e+09 7.330000e+08
183 4.049414e+11 1.408439e+11
184 NA NA
185 5.387859e+13 1.505121e+13
186 8.806086e+10 3.256853e+10
187 4.333633e+11 2.264740e+11
188 1.073623e+10 6.352239e+09
189 3.209095e+11 6.262456e+10
190 2.789000e+08 NA
191 6.698440e+10 2.932200e+10
192 2.475134e+10 NA
193 3.792534e+10 1.332894e+10
194 2.283235e+11 5.229617e+10
195 3.768233e+11 1.524586e+11
196 5.960546e+11 2.950076e+11
197 2.399869e+11 1.033295e+11
198 5.087935e+13 1.454793e+13
199 1.393743e+12 3.635181e+11
200 1.051264e+11 4.942410e+10
201 1.758376e+11 6.676978e+10
202 2.510193e+11 1.112087e+11
203 1.693114e+12 3.520885e+11
204 1.035633e+10 3.741294e+09
205 9.129445e+08 4.409317e+08
206 1.616189e+09 2.315474e+09
207 4.274250e+08 NA
208 8.036163e+11 2.189408e+11
209 2.339881e+10 9.186798e+09
210 5.151422e+10 3.139466e+10
211 1.684373e+09 1.927533e+09
212 4.076579e+09 1.546805e+09
213 3.754727e+11 5.501926e+11
214 NA NA
215 1.057204e+11 9.681579e+10
216 5.433159e+10 4.080292e+10
217 5.215279e+11 2.766322e+11
218 1.619155e+09 7.529302e+08
219 6.485000e+09 5.423000e+09
220 3.885320e+11 1.039606e+11
221 3.653951e+12 7.859776e+11
222 3.653951e+12 7.859776e+11
223 NA NA
224 1.394320e+12 4.457221e+11
225 8.901499e+10 2.456991e+10
226 1.107841e+09 NA
227 2.094202e+09 NA
228 NA NA
229 9.101497e+08 NA
230 1.794052e+12 4.700084e+11
231 1.795736e+12 4.719455e+11
232 1.795736e+12 4.719455e+11
233 3.233808e+10 1.902356e+08
234 4.016041e+09 NA
235 5.338795e+11 2.329029e+11
236 7.213691e+11 4.123506e+11
237 2.244330e+10 6.506179e+09
238 8.300785e+09 3.408724e+09
239 6.113687e+10 1.036347e+10
240 5.440811e+11 2.729166e+11
241 2.028552e+09 1.004126e+09
242 7.220395e+09 2.260741e+09
243 5.120577e+08 3.338290e+08
244 2.384956e+10 NA
245 4.190611e+10 2.362762e+10
246 7.599374e+11 2.292087e+11
247 4.523143e+10 NA
248 1.197415e+09 NA
249 5.422315e+07 NA
250 3.535306e+10 7.866762e+09
251 1.538830e+11 7.583283e+10
252 4.179897e+11 2.955998e+11
253 2.857058e+12 9.391877e+11
254 2.138098e+13 3.117235e+12
255 2.368174e+13 5.166816e+12
256 6.123115e+10 1.338320e+10
257 5.990767e+10 2.662051e+10
258 9.365263e+08 4.592509e+08
259 NA NA
260 3.343653e+11 2.659763e+11
261 4.117000e+09 4.148000e+09
262 1.713350e+10 9.161700e+09
263 8.764526e+13 2.434813e+13
264 NA NA
265 2.330867e+10 7.961078e+09
266 2.183223e+10 5.572484e+09
ggplot
Kita declare dulu dengan ggplot:
ggplot(data=dat,aes(x=PDB,y=import))
Ini akan memberi tahu ggplot bahwa kita ingin membuat grafik dari data “dat”, di mana PDB jadi x-nya dan import jadi y-nya.
Tapi ini saja tidak cukup. Anda harus secara eksplisit memberi tahu bahwa anda ingin membuat titik (scatterplot). Tambahkan + geom_point() di belakangnya.
Untuk memberi label di sumbu X, Y dan judul tabel, anda dapat menggunakan labs
ggplot(data=dat,aes(x=PDB,y=import)) +geom_point() +# setiap nambah command, selalu kasih tanda +labs(title="tabel 1. hubungan antara impor dan PDB",x="Produk Domestik Bruto, current US$ million",y="Nilai impor, current US$ million",caption ="sumber: World Development Indicators, World Bank") # yang terakhir ga perlu +
Cara save ggplot
pilih export, save as png. filenya akan muncul di folder anda.
Theme BW
Anda juga bisa nambah theme utk ganti kosmetik grafik.
ggplot(data=dat,aes(x=PDB,y=import)) +geom_point() +# setiap nambah command, selalu kasih tanda +labs(title="tabel 1. hubungan antara impor dan PDB",x="Produk Domestik Bruto, current US$ million",y="Nilai impor, current US$ million",caption ="sumber: World Development Indicators, World Bank") +theme_bw()
ggplot(data=dat,aes(x=PDB,y=import)) +geom_point() +# setiap nambah command, selalu kasih tanda +labs(title="tabel 1. hubungan antara impor dan PDB",x="Produk Domestik Bruto, current US$ million",y="Nilai impor, current US$ million",caption ="sumber: World Development Indicators, World Bank") +theme_classic()
Size & color
Anda bisa mewarnai dan ganti size di geom_point
ggplot(data=dat,aes(x=PDB,y=import)) +geom_point(color="red",size=2) +# setiap nambah command, selalu kasih tanda +labs(title="tabel 1. hubungan antara impor dan PDB",x="Produk Domestik Bruto, current US$ million",y="Nilai impor, current US$ million",caption ="sumber: World Development Indicators, World Bank") +theme_classic()
Time Series
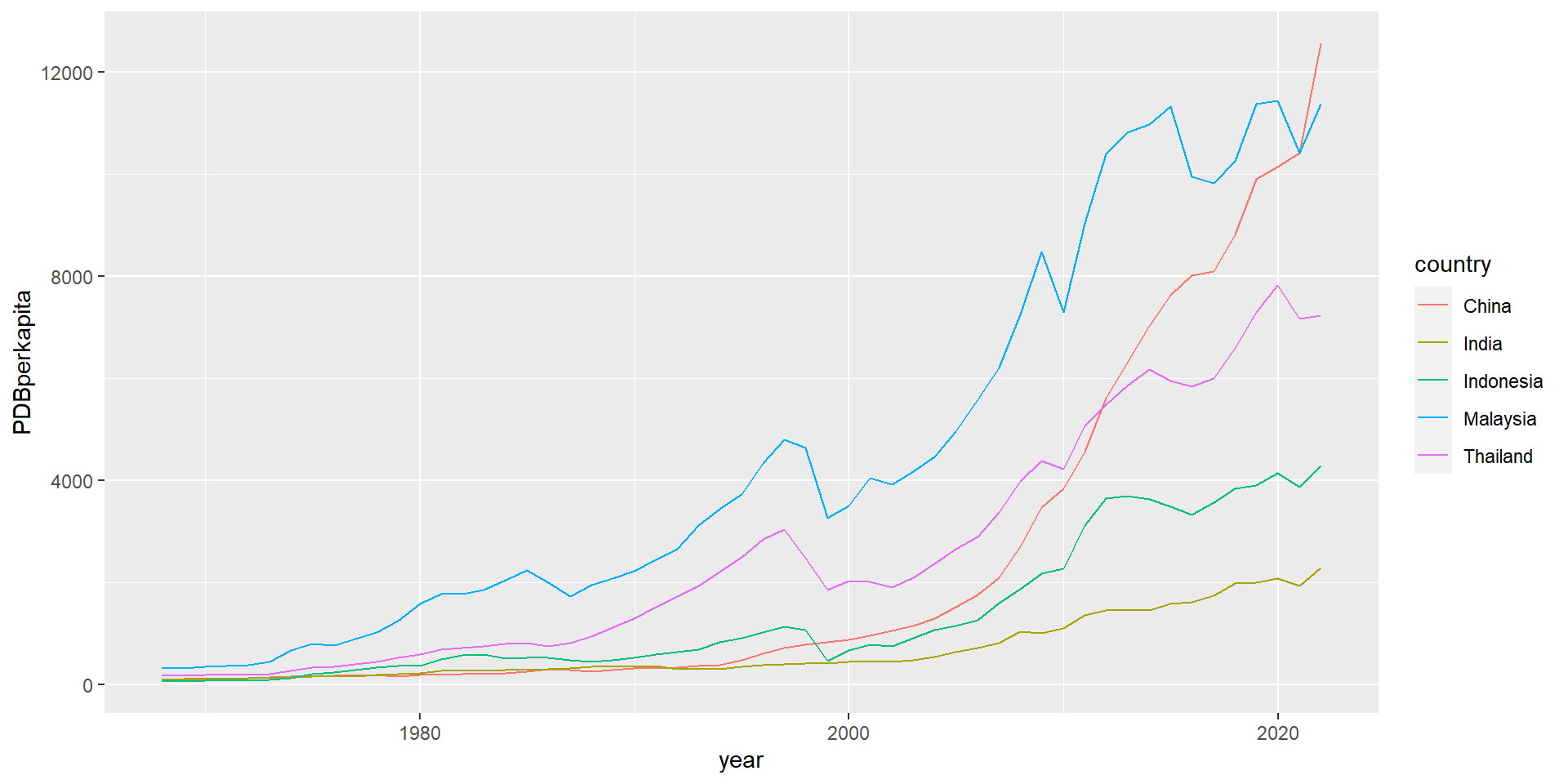
setelah scatterplot, kita akan coba line graph.
Line graph biasanya digunakan untuk data time series atau panel.
pengguna ggplot harus menggunakan format data “long”.
kolom waktu harus menggunakan tipe “tss” atau datetime.
Datetime
Format long dan wide dibahas di pertemuan 7.
Untuk datetime, anda harus memastikan variable waktu (tahun, bulan, dll) harus dalam bentuk tss.
Kadang-kadang saat kita pakai read_excel() atau read_csv(), R tidak membaca kolom waktu sebagai “tss”, tapi malah sebagai “chr” (karakter) atau bahkan numerik (dbl, fl64, dst)
Jika bentuknya “chr”, harus kita ubah ke “tss” dengan as.Date()
Datetime
library(readxl)dat<-read_excel("latihan7.xlsx")dat$year<-as.Date(dat$year,format="%Y") # mengubah year dari chr ke tss
Di latihan7.xlsx, kolom “year” bentuknya adalah “chr”. Dengan as.Date(), kita mengubah kolom “year” dari “chr” jadi “tss”.
sub-command “format” memberitau kita bahwa year itu merupakan tahun.
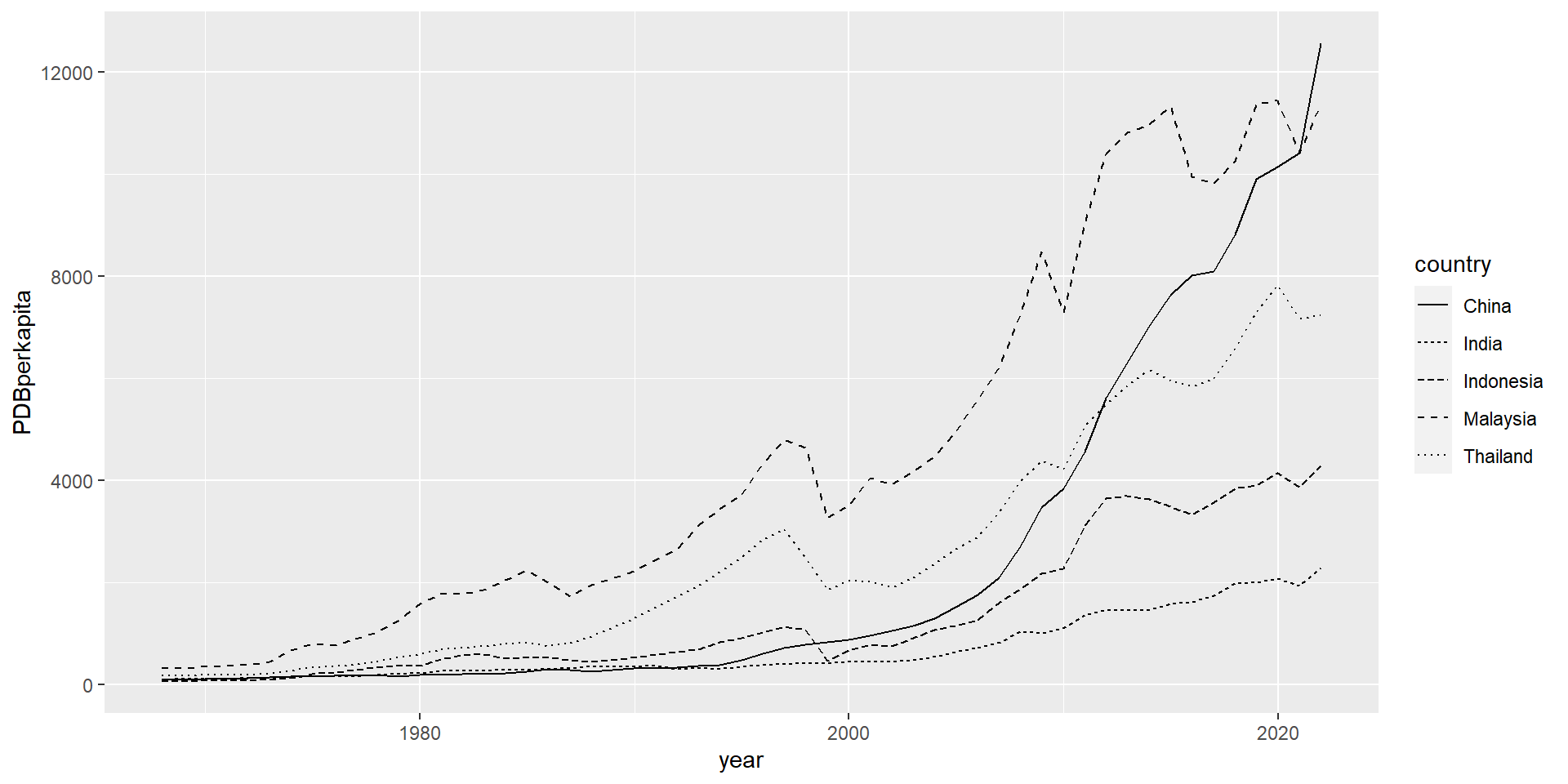
Harus selalu diingat nama variabelnya, mana yang jadi x, y, dan color/linetype. Anda juga bisa pakai labs dan theme sama seperti di contoh scatterplot.
More on ggplot
masih ada banyak jurus-jurus di ggplot bahkan bisa buat gambar hal-hal yang bukan data.
Ada banyak built-in theme yang bisa dilihat di sini
Tapi untuk saat ini, cukup segini dulu yang dipelajari.
Jika anda tertarik lebih lanjut mempelajari ggplot, anda dapat gunakan google.