Menarik data COVID-19 dari ourworldindata
Saya akan contohkan pake data covid-nya Our World in Data1 yang datanya bisa diakses siapa saja dengan gratis.
Python
url='https://covid.ourworldindata.org/data/owid-covid-data.csv' # simpan url
df=pd.read_csv(url, parse_dates=['date']) # download dari url. parse_dates untuk menjadikan kolom date jadi tipe waktu
df.head(10) # menampilkan 10 baris paling atas
| iso_code | continent | location | date | total_cases | new_cases | new_cases_smoothed | total_deaths | new_deaths | new_deaths_smoothed | ... | extreme_poverty | cardiovasc_death_rate | diabetes_prevalence | female_smokers | male_smokers | handwashing_facilities | hospital_beds_per_thousand | life_expectancy | human_development_index | excess_mortality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AFG | Asia | Afghanistan | 2020-02-24 | 1.0 | 1.0 | NaN | NaN | NaN | NaN | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
| 1 | AFG | Asia | Afghanistan | 2020-02-25 | 1.0 | 0.0 | NaN | NaN | NaN | NaN | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
| 2 | AFG | Asia | Afghanistan | 2020-02-26 | 1.0 | 0.0 | NaN | NaN | NaN | NaN | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
| 3 | AFG | Asia | Afghanistan | 2020-02-27 | 1.0 | 0.0 | NaN | NaN | NaN | NaN | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
| 4 | AFG | Asia | Afghanistan | 2020-02-28 | 1.0 | 0.0 | NaN | NaN | NaN | NaN | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
| 5 | AFG | Asia | Afghanistan | 2020-02-29 | 1.0 | 0.0 | 0.143 | NaN | NaN | 0.0 | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
| 6 | AFG | Asia | Afghanistan | 2020-03-01 | 1.0 | 0.0 | 0.143 | NaN | NaN | 0.0 | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
| 7 | AFG | Asia | Afghanistan | 2020-03-02 | 1.0 | 0.0 | 0.000 | NaN | NaN | 0.0 | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
| 8 | AFG | Asia | Afghanistan | 2020-03-03 | 2.0 | 1.0 | 0.143 | NaN | NaN | 0.0 | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
| 9 | AFG | Asia | Afghanistan | 2020-03-04 | 4.0 | 2.0 | 0.429 | NaN | NaN | 0.0 | ... | NaN | 597.029 | 9.59 | NaN | NaN | 37.746 | 0.5 | 64.83 | 0.511 | NaN |
10 rows × 60 columns
Karena kolomnya banyak banget, kita list aja nama-nama kolom yang ada di sini, supaya tau variabel apa yang mau kita plot. Lagian cape juga kalo harus panggil lagi dan lagi dengan variabel dan kolom sebanyak itu kan. Mendingan kita subset aja datanya.
df.columns # untuk panggil list dari nama-nama variabel
Index(['iso_code', 'continent', 'location', 'date', 'total_cases', 'new_cases',
'new_cases_smoothed', 'total_deaths', 'new_deaths',
'new_deaths_smoothed', 'total_cases_per_million',
'new_cases_per_million', 'new_cases_smoothed_per_million',
'total_deaths_per_million', 'new_deaths_per_million',
'new_deaths_smoothed_per_million', 'reproduction_rate', 'icu_patients',
'icu_patients_per_million', 'hosp_patients',
'hosp_patients_per_million', 'weekly_icu_admissions',
'weekly_icu_admissions_per_million', 'weekly_hosp_admissions',
'weekly_hosp_admissions_per_million', 'new_tests', 'total_tests',
'total_tests_per_thousand', 'new_tests_per_thousand',
'new_tests_smoothed', 'new_tests_smoothed_per_thousand',
'positive_rate', 'tests_per_case', 'tests_units', 'total_vaccinations',
'people_vaccinated', 'people_fully_vaccinated', 'new_vaccinations',
'new_vaccinations_smoothed', 'total_vaccinations_per_hundred',
'people_vaccinated_per_hundred', 'people_fully_vaccinated_per_hundred',
'new_vaccinations_smoothed_per_million', 'stringency_index',
'population', 'population_density', 'median_age', 'aged_65_older',
'aged_70_older', 'gdp_per_capita', 'extreme_poverty',
'cardiovasc_death_rate', 'diabetes_prevalence', 'female_smokers',
'male_smokers', 'handwashing_facilities', 'hospital_beds_per_thousand',
'life_expectancy', 'human_development_index', 'excess_mortality'],
dtype='object')
Wah gilaaa banyak banget ya nama variabelnya. Cape banget pasti ngumpulin ini semua. Hebat emang Hannah Ritchie dkk. Oke deh sekarang coba kita ngelihat jumlah kasus baru. ada setidaknya tiga nama variabel yang bisa diambil, yaitu new_cases dan new_cases_smoothed. Kalau dari namanya sih ketaker ya kalo yang smoothed itu kayaknya moving average, alias diambil alusnya dari data new_cases yang bisa jadi sangat volatil. Sering terjadi di data harian gini karena, misalnya, setiap hari senin selalu membludak, sementara sabtu minggu selalu sepi. Apa malah kebalik, sabtu minggu malah rame karena orang libur jadi bisa datang ke tempat testing. Yg jelas ada pattern mingguan yang bikin data harian jadi volatil. Nah kita ambil dua-duanya yok!
Kalau kamu cuma tertarik ambil data Indonesia, maka jangan lupa diambil yang Indonesia aja.
indo=df[["iso_code","date","new_cases","new_cases_smoothed"]].query('iso_code == "IDN"')
Saatnya diplot!
sns.lineplot(data=indo,x='date',y='new_cases')
sns.lineplot(data=indo,x='date',y='new_cases_smoothed')
plt.xticks(rotation=45)
(array([18322., 18383., 18444., 18506., 18567., 18628., 18687., 18748.,
18809.]),
[Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, '')])
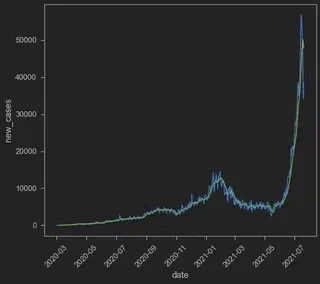
kayaknya new_cases_smoothed ini adalah 7-day rollong average. Seperti yang saya tulis sebelumnya, data harian biasanya punya tren mingguan. Makanya dibuat rolling average dalam 7 hari adalah hal yang umum dilakukan. Yok kita cek! Saya pake rolling averagenya panda yang saya contek di sini dengan tambahan shift(-3) untuk mundurin NaN 3 hari ke depan dan 3 hari ke belakang.
indo['cases_7day_ave'] = indo.new_cases.rolling(7).mean().shift(-3)
indo.head(10)
| iso_code | date | new_cases | new_cases_smoothed | cases_7day_ave | |
|---|---|---|---|---|---|
| 43498 | IDN | 2020-03-02 | 2.0 | NaN | NaN |
| 43499 | IDN | 2020-03-03 | 0.0 | NaN | NaN |
| 43500 | IDN | 2020-03-04 | 0.0 | NaN | NaN |
| 43501 | IDN | 2020-03-05 | 0.0 | NaN | 0.857143 |
| 43502 | IDN | 2020-03-06 | 2.0 | NaN | 2.428571 |
| 43503 | IDN | 2020-03-07 | 0.0 | 0.571 | 3.571429 |
| 43504 | IDN | 2020-03-08 | 2.0 | 0.857 | 4.571429 |
| 43505 | IDN | 2020-03-09 | 13.0 | 2.429 | 4.571429 |
| 43506 | IDN | 2020-03-10 | 8.0 | 3.571 | 9.285714 |
| 43507 | IDN | 2020-03-11 | 7.0 | 4.571 | 13.142857 |
Seperti bisa dilihat di atas, sepertinya bener new_cases_smoothed adalah 7-day average soalnya ada 6 NaN berturut-turut. Kayaknya bedanya adalah sama si Ritchie dkk nggak di-shift. ya gpp kita tes plot aja yuk.
sns.lineplot(data=indo,x='date',y='new_cases')
sns.lineplot(data=indo,x='date',y='new_cases_smoothed')
sns.lineplot(data=indo,x='date',y='cases_7day_ave')
plt.xticks(rotation=45)
plt.legend(['new cases','new cases smoothed','7-day average bikinan sendiri'])
plt.ylabel('kasus')
plt.xlabel('tanggal')
Text(0.5, 1.0, 'Plot kasus baru di Indonesia \n')
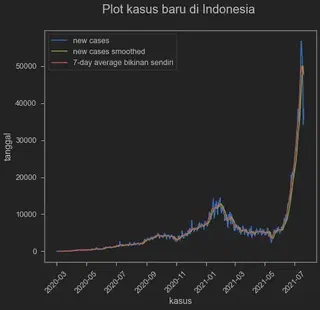
berhubung satu setengah tahun adalah waktu yang panjang (gila lama juga ya covid ga beres-beres), maka kita potong aja deh tahun 2020. Kalo dilihat di atas sih sepertinya first wave yang sebenarnya malah baru keliatna di awal-awal 2021 ya. Oh iya jangan lupa Indonesia juga undertesting kalau dilihat positive rate. Anyway, ayo kita pangkas lagi data kita di indo dengan membuah tahun 2020. Oh iya satu lagi, kita pakai aja new_cases_smoothed yang dari aslinya ga usah kita buat rolling average sendiri.
indo2=indo.query('date>20210101') # ambil hanya setelah 1 Januari 2021
# lalu kita plot persis seperti di atas
sns.lineplot(data=indo2,x='date',y='new_cases')
sns.lineplot(data=indo2,x='date',y='new_cases_smoothed')
plt.xticks(rotation=45)
plt.legend(['new cases','new cases smoothed','7-day average bikinan sendiri'])
plt.ylabel('kasus')
plt.xlabel('tanggal')
Text(0.5, 0, 'tanggal')
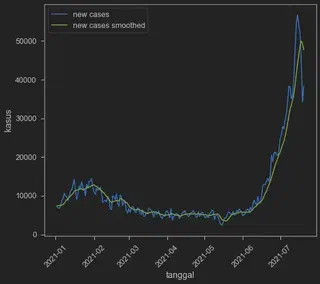
Begitulah! Abis ini kita tinggal main-main sama data ini. Jangan lupa bahwa data potongannya bisa kita save ke mikrosop eksel dengan indo.to_excel("output.xlsx"), atau ke csv dengan indo.to_csv("indo.csv", index=False).
r
Membaca dengan r dan langsung divisualisasi juga tidak kalah mudah!
Hannah Ritchie, Esteban Ortiz-Ospina, Diana Beltekian, Edouard Mathieu, Joe Hasell, Bobbie Macdonald, Charlie Giattino, Cameron Appel, Lucas Rodés-Guirao and Max Roser (2020) - “Coronavirus Pandemic (COVID-19)”. Published online at OurWorldInData.org. Retrieved from: ‘https://ourworldindata.org/coronavirus' [Online Resource] ↩︎